安全功能之系统退出后JWT令牌失效
· 阅读需 0 分钟

浏览量:加载中...
现在国内越来越重视系统安全,最近我们公司在做第三方测试过程中对系统安全、系统性能等做出了严格的要求,并进行了很大的整改,就从这篇文章开始总结一下最近三个月以及以后还会继续整改的涉及系统安全的相关测试漏洞的修改方案,相信这些问题会帮助到大家,尤其是比较大型的政府项目,对系统安全更加注重。
在互联网和新兴技术高速发展的今天,数据信息充斥在各行各业中,并发挥着重要的作用。然而,在享受信息化时代带来便利的同时,数据安全问题也成为大家关注的焦点。无论是从toG、toB、toC的各业务场景来看,还是从网络安全(CyberSecurity)的架构来看,数据安全(DataSecurity)都是一个主要的组成部分,而且在新兴技术日新月异的数据时代变得越来越重要,范围也越来越大。 ------- 引自 《数据安全架构设计与实战》
无论是进行产品的安全架构设计或评估,还是规划安全技术体系架构的时候,都有几个需要重点关注的逻辑模块,它们可以在逻辑上视为安全架构的核心元素。 以应用/产品为例,核心元素包括: ■ 身份认证(Authentication):用户主体是谁? ■ 授权(Authorization):授予某些用户主体允许或拒绝访问客体的权限。 ■ 访问控制(Access Control):控制措施以及是否放行的执行者。 ■ 可审计(Auditable):形成可供追溯的操作日志。 ■ 资产保护(Asset Protection):资产的保密性、完整性、可用性保障
我们在测试过程中涉及到了对数据传输加密、数据存储加密、对称加密、非对称加密、SM2、SM3、SM4国密加密,CA证书等等
什么是非对称加密呢?
非对称加密是一种密码学技术,与传统的对称加密不同,它使用一对密钥来进行加密和解密操作,这对密钥分别称为公钥和私钥。这两个密钥是数学上相关联的,但却不能通过已知一个密钥来轻松地推导出另一个密钥。
我们可以想象一下,就像你有一把锁和一把钥匙,任何人都可以得到这把锁,但只有你有这把唯一的钥匙。任何人都可以使用这把锁将信息锁住,但只有你能够使用你的独特的钥匙来解锁这个信息。
举例来说,考虑用户密码的存储问题。通过非对称加密的方式,可以将用户密码加密后写入数据库。当用户再次登录时,系统将客户端输入的明文密码使用相同的非对称加密方式加密,然后与数据库中的密文进行比对。这样的设计大大提高了安全性,即使数据库被攻击,攻击者也无法轻松获取用户的明文密码。 国密SM2加密方式就是非对称加密的。下面是国密SM2加密工具的源码:
/*椭圆曲线非对称加密算法*/
public class SM2Util {
public static final String key_pubk= "pub";
public static final String key_prik= "pri";
private static SM2 sm2 = SM2.instance();
private static final String DEFAULT_PRIVATE_KEY = "27cd96b1500f8330fc523e7c47ef02a";
private static final String DEFAULT_PUBLIC_KEY = "047ec86bb18f57714e6c5c72383c5b122";
/**
* 生成公私钥
* @return
*/
public static Map<String,String> generateKeyPair() {
Map<String,String> result = new HashMap<>();
AsymmetricCipherKeyPair key = sm2.eccKeyPairGenerator.generateKeyPair();
BigInteger privateKey = ((ECPrivateKeyParameters)key.getPrivate()).getD();
ECPoint publicKey = ((ECPublicKeyParameters)key.getPublic()).getQ();
String pubk = new String(Hex.encode(publicKey.getEncoded(false)), StandardCharsets.UTF_8);
String prik = new String(Hex.encode(privateKey.toByteArray()), StandardCharsets.UTF_8);
result.put(key_pubk, pubk);
result.put(key_prik, prik);
return result;
}
/**
* 获取默认公钥
* @return
*/
public static String getDefaultPublicKey() {
return DEFAULT_PUBLIC_KEY;
}
/**
* 获取默认私钥
* @return
*/
public static String getDefaultPrivateKey() {
return DEFAULT_PRIVATE_KEY;
}
/**
* 加密
* @param data
* @param publicKey
* @return
*/
protected static byte[] encrypt(String data, byte[] publicKey) {
if (StringUtils.isBlank(data)) {
return null;
}
SM2Cipher cipher = new SM2Cipher();
// C1
byte[] c1Bytes = new byte[65];
ECPoint c1 = cipher.encryptInit(sm2, sm2.eccCurve.decodePoint(publicKey));
c1Bytes = c1.getEncoded(false);
// C2
byte[] c2Bytes = data.getBytes(StandardCharsets.UTF_8);
cipher.encrypt(c2Bytes);
// C3
byte[] c3Bytes = new byte[32];
cipher.doFinal(c3Bytes);
byte[] encryptData = new byte[c1Bytes.length + c2Bytes.length + c3Bytes.length];
System.arraycopy(c1Bytes, 0, encryptData, 0, c1Bytes.length);
System.arraycopy(c2Bytes, 0, encryptData, c1Bytes.length, c2Bytes.length);
System.arraycopy(c3Bytes, 0, encryptData, c1Bytes.length + c2Bytes.length, c3Bytes.length);
return encryptData;
}
/**
* 加密
* @param data
* @param publicKey
* @return
*/
public static byte[] encrypt(String data, String publicKey) {
return encrypt(data, HexUtil.hexToByte(publicKey));
}
/**
* 加密
* @param data
* @param publicKey
* @return
*/
public static byte[] encrypt(byte[] data, String publicKey) {
return encrypt(new String(data, StandardCharsets.UTF_8), HexUtil.hexToByte(publicKey));
}
/**
* 加密
* @param data
* @param publicKey
* @return
*/
public static String encryptToHexString(String data, String publicKey) {
return HexUtil.byteToHex(encrypt(data, HexUtil.hexToByte(publicKey)));
}
/**
* 加密
* @param data
* @param publicKey
* @return
*/
public static String encryptToHexString(byte[] data, String publicKey) {
return HexUtil.byteToHex(encrypt(new String(data, StandardCharsets.UTF_8), HexUtil.hexToByte(publicKey)));
}
/**
* 解密
* @param encryptedData
* @param privateKey
* @return
*/
protected static byte[] decrypt(byte[] encryptedData, byte[] privateKey) {
if (ArrayUtils.isEmpty(encryptedData)) {
return null;
}
SM2Cipher cipher = new SM2Cipher();
// C1
byte[] c1Bytes = new byte[65];
System.arraycopy(encryptedData, 0, c1Bytes, 0, c1Bytes.length);
ECPoint c1 = sm2.eccCurve.decodePoint(c1Bytes).normalize();
// C3
byte[] c3Bytes = new byte[32];
System.arraycopy(encryptedData, encryptedData.length - 32, c3Bytes, 0, 32);
// C2
int c2Len = encryptedData.length - 65 - 32;
byte[] c2Bytes = new byte[c2Len];
System.arraycopy(encryptedData, 65, c2Bytes, 0, c2Len);
cipher.decryptInit(new BigInteger(1, privateKey), c1);
cipher.decrypt(c2Bytes);
cipher.doFinal(c3Bytes);
return c2Bytes;
}
/**
* 解密
* @param encryptedData
* @param privateKey
* @return
*/
public static byte[] decrypt(byte[] encryptedData, String privateKey) {
return decrypt(encryptedData, HexUtil.hexToByte(privateKey));
}
/**
* 解密
* @param encryptedData
* @param privateKey
* @return
*/
public static String decryptToString(byte[] encryptedData, String privateKey) {
return new String(decrypt(encryptedData, HexUtil.hexToByte(privateKey)), StandardCharsets.UTF_8);
}
/**
* 解密
* @param encryptedData
* @param privateKey
* @return
*/
public static String decryptToString(String encryptedData, String privateKey) {
return new String(decrypt(Hex.decode(encryptedData), HexUtil.hexToByte(privateKey)), StandardCharsets.UTF_8);
}
}
此外,CA(Certificate Authority,证书颁发机构)机构通常也使用非对称加密的方式来确保数字证书的安全性。CA机构在数字证书颁发过程中起到了信任的中介角色,其操作基于公钥基础设施(PKI)。
下面是CA机构使用非对称加密的一般流程:
非对称加密的优势在于它提供了更高的安全性。即使在公共环境下传输公钥,也无法通过公钥轻松计算出私钥。这使得非对称加密在安全地实现身份验证、数字签名和加密通信等场景中发挥重要作用。
相对的,什么是对称加密呢?
对称加密是一种加密算法,它使用相同的密钥同时进行数据的加密和解密。这意味着在对称加密中,使用加密和解密操作的相同密钥。对称加密算法在加密和解密的过程中都使用相同的密钥,因此密钥的保管和分发变得至关重要。 我们了解的国密SM4就是采用的对称加密的方式实现的,源码工具如下:
/**
* (分组密码算法)国密对称加密算法
*/
@Slf4j
public abstract class SM4Util {
static {
Security.addProvider(new BouncyCastleProvider());
}
private static final Charset ENCODING = StandardCharsets.UTF_8;
public static final String ALGORITHM_NAME = "SM4";
// 加密算法/分组加密模式/分组填充方式
public static final String ALGORITHM_NAME_ECB_PADDING = "SM4/ECB/PKCS5Padding";
public static final String ALGORITHM_NAME_CBC_PADDING = "SM4/CBC/PKCS5Padding";
// 128-32位16进制;256-64位16进制
public static final int DEFAULT_KEY_SIZE = 128;
public static final String DEFAULT_KEY = "86C63180C2806ED1F47B859DE501215B";
public static final String DEFAULT_IV = "8F5CB6272B594B53AD1A2197361378DC";
private static Cipher generateCipherECB(String algorithmName, int mode, byte[] key) throws Exception {
Cipher cipher = Cipher.getInstance(algorithmName, BouncyCastleProvider.PROVIDER_NAME);
cipher.init(mode, new SecretKeySpec(key, ALGORITHM_NAME));
return cipher;
}
private static Cipher generateCipherCBC(String algorithmName, int mode, byte[] key, byte[] iv) throws Exception {
Cipher cipher = Cipher.getInstance(algorithmName, BouncyCastleProvider.PROVIDER_NAME);
cipher.init(mode, new SecretKeySpec(key, ALGORITHM_NAME), new IvParameterSpec(iv));
return cipher;
}
public static String generateKey() {
try {
return HexUtil.byteToHex(generateKey(DEFAULT_KEY_SIZE));
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return null;
}
public static byte[] generateKey(int keySize) throws Exception {
KeyGenerator kg = KeyGenerator.getInstance(ALGORITHM_NAME, BouncyCastleProvider.PROVIDER_NAME);
kg.init(keySize, new SecureRandom());
return kg.generateKey().getEncoded();
}
protected static byte[] encryptECBPadding(byte[] data, byte[] key) throws Exception {
Cipher cipher = generateCipherECB(ALGORITHM_NAME_ECB_PADDING, Cipher.ENCRYPT_MODE, key);
return cipher.doFinal(data);
}
protected static byte[] decryptECBPadding(byte[] encrypted, byte[] key) throws Exception {
Cipher cipher = generateCipherECB(ALGORITHM_NAME_ECB_PADDING, Cipher.DECRYPT_MODE, key);
return cipher.doFinal(encrypted);
}
protected static byte[] encryptCBCPadding(byte[] data, byte[] key, byte[] iv) throws Exception {
Cipher cipher = generateCipherCBC(ALGORITHM_NAME_CBC_PADDING, Cipher.ENCRYPT_MODE, key, iv);
return cipher.doFinal(data);
}
protected static byte[] decryptCBCPadding(byte[] encrypted, byte[] key, byte[] iv) throws Exception {
Cipher cipher = generateCipherCBC(ALGORITHM_NAME_CBC_PADDING, Cipher.DECRYPT_MODE, key, iv);
return cipher.doFinal(encrypted);
}
public static String encrypt(String source) {
return encrypt(source, DEFAULT_KEY);
}
public static String encrypt(byte[] source) {
return encrypt(source, DEFAULT_KEY);
}
public static String encrypt(String source, String hexKey) {
return encrypt(source.getBytes(ENCODING), hexKey);
}
public static String encrypt(byte[] source, String hexKey) {
byte[] cipherArray;
try {
cipherArray = encryptECBPadding(source, ByteUtils.fromHexString(hexKey));
return ByteUtils.toHexString(cipherArray);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return null;
}
public static byte[] decrypt(String encrypted) {
return decrypt(encrypted, DEFAULT_KEY);
}
public static String decryptToString(String encrypted) {
return decryptToString(encrypted, DEFAULT_KEY);
}
public static String decryptToString(String encrypted, String hexKey) {
return new String(decrypt(encrypted, hexKey), ENCODING);
}
public static byte[] decrypt(String encrypted, String hexKey) {
try {
return decryptECBPadding(ByteUtils.fromHexString(encrypted), ByteUtils.fromHexString(hexKey));
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return encrypted.getBytes(StandardCharsets.UTF_8);
}
public static String encrypt(String source, String hexKey, String iv) {
return encrypt(source.getBytes(ENCODING), hexKey, iv);
}
public static String encrypt(byte[] source, String hexKey, String iv) {
byte[] cipherArray;
try {
cipherArray = encryptCBCPadding(
source
, ByteUtils.fromHexString(hexKey)
, ByteUtils.fromHexString(iv));
return ByteUtils.toHexString(cipherArray);
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new RuntimeException("数据加密失败", e);
}
}
public static String decryptToString(String encrypted, String hexKey, String iv) {
return new String(decrypt(encrypted, hexKey, iv), ENCODING);
}
public static byte[] decrypt(String encrypted, String hexKey, String iv) {
try {
if (StringUtils.isBlank(encrypted)) {
return new byte[] {};
}
return decryptCBCPadding(
ByteUtils.fromHexString(encrypted)
, ByteUtils.fromHexString(hexKey)
, ByteUtils.fromHexString(iv));
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return encrypted.getBytes(StandardCharsets.UTF_8);
}
}
相信你也一定听过国密SM3算法,它是对称加�密还是非对称加密呢? 其实SM3是一种密码杂凑算法,用于生成消息的哈希值,主要用于数据完整性验证、数字签名等场景,而不是进行加密和解密操作。所以它既不是对称加密也不是非对称加密,它常常与SM2与SM4组合一起使用,可以把它看成一个随机数。 例如: 系统数据存储加密应采用SM3+SM4的实现方式。 系统数据传输加密应采用SM2+SM3的实现方式。
总结 在系统安全测试中,我们通过采用多层加密算法、合理的安全架构设计以及严格的数据安全措施,提高了系统在身份认证、授权、访问控制、审计和资产保护等方面的安全性。这有助于在互联网和新兴技术时代中更好地处理数据安全问题,特别适用于大型政府项目等对安全性要求较高的场景。数据安全相关的知识属于另一个领域了,知识点真是深不可测,还需要平时多学习,积累更多的知识储备才行。
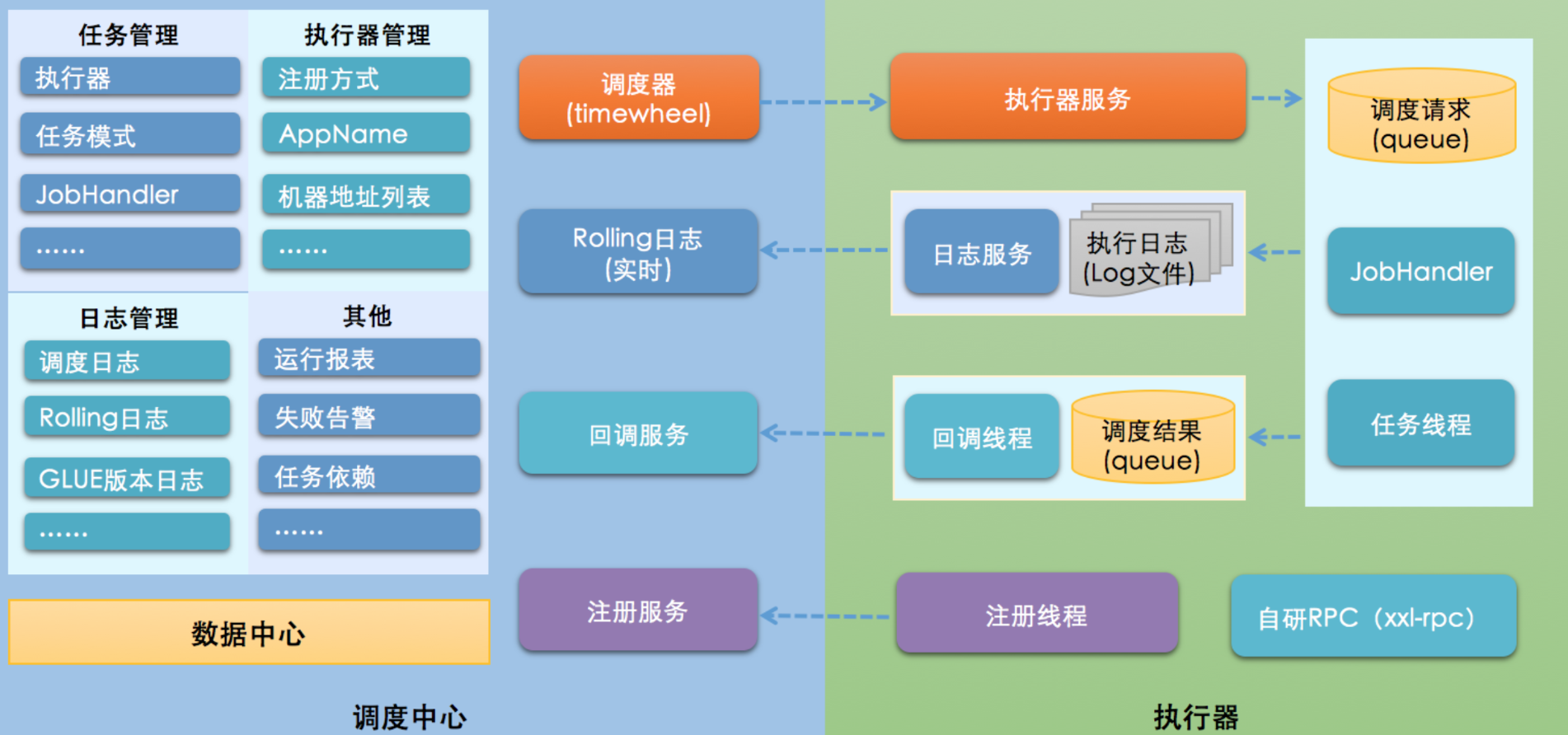
起因:传统的定时任务Timer、Quartz等存在很多缺陷,不支持集群、不支持统计、没有管理的平台、也没有报警、监控等等。因此我们要使用分布式的调度系统,去填补这一系列缺陷,之前我们的系统用到了rabbitMQ消息队列去用于分布式任务调度、事件驱动等场景。通过RabbitMQ,任务调度系统可以将任务分发到多个节点,并获取任务执行结果。但是它也有弊端,就是没有一个完整的任务调度平台,不能很好的对任务执行情况进行监控和管理,所以最后选择了XXL-Job去升级医院系统的定时给就诊人发送消息等功能。
xxl-job:https://github.com/xuxueli/xxl-job
elastic-job:https://shardingsphere.apache.org/elasticjob/
| 对比项 | XXL-JOB | elastic-job |
|---|---|---|
| 并行调度 | 调度系统多线程并�行 | 任务分片的方式并行 |
| 弹性扩容 | 使用Quartz基于数据库分布式功能 | 通过zookeeper保证 |
| 高可用 | 通过DB锁保证 | 通过zookeeper保证 |
| 阻塞策略 | 单机串行/丢弃后续的调度/覆盖之前的调度 | 执行超过zookeeper的session timeout时间的话,会被清除,重新进行分片 |
| 动态分片策略 | 以执行器为维度进行分片、支持动态的扩容 | 平均分配/作业名hash分配/自定义策略 |
| 失败处理策略 | 失败告警/失败重试 | 执行完毕后主动获取未分配分片任务 服务器下线后主动寻找可以用的服务器执行任务 |
| 监控 | 支持 | 支持 |
| 日志 | 支持 | 支持 |
综合考虑,最后我们选择了xxl-job这一解决方法,下面是一个小demo,用于整合xxl-job到spring微服务项目中得以应用的最佳实践。

Maven3+、jdk1.8+、mysql5.7+
https://github.com/xuxueli/xxl-job.git 版本:2.3.0
/xxl-job/doc/db/tables_xxl_job.sql
调度中心项目:xxl-job-admin 修改该模块下的配置文件并启动server
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin
......
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
......
### xxl-job, access token
xxl.job.accessToken=jiguanchen.space


创建任务:

# xxl-job任务调度配置
xxl:
job:
admin:
addresses: http://127.0.0.1:8080/xxl-job-admin #调度中心部署地址,多个配置逗号分隔 "http://address01,http://address02"
accessToken: jiguanchen.space #执行器token,非空时启用 xxl-job, access token
executor:
appname: yygh-order # 执行器app名称,和控制台那边配置一样的名称,不然注册不上去
port: 6666 # 执行器的端口
logpath: ./data/logs/xxl-job/executor # 执行器日志文件存储路径,需要对该路径拥有读写权限;为空则使用默认路径
logretentiondays: 30 # 执行器日志保存天数
# [选填]执行器IP :默认为空表示自动获取IP(即springboot容器的ip和端口,可以自动获取,也可以指定),
# 多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务",
ip:
# [选填]执行器注册:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题
address:
<!-- xxl_job分布式调度 -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
package space.jachen.yygh.order.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author JaChen
* @date 2023/2/14 15:46
*/
@Configuration
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
添加hander处理器
package space.jachen.yygh.order.handler;
/**
* @author JaChen
* @date 2024/2/14 15:53
*/
@Component
public class MyJobHandler {
@Autowired
private RabbitService rabbitService;
@Autowired
private OrderInfoMapper orderInfoMapper;
/**
* 就诊提醒的handler方法
*
* @param param null
* @return ReturnT<String>
*/
@XxlJob(value = "demoJobHandler1",init = "init",destroy = "destroy")
public ReturnT<String> execute(String param){
System.out.println("execute方法执行了 ====》 ");
// 获取查询的时间
DateTime dateTime = new DateTime().plusDays(1);
String dateString = dateTime.toString("yyyy-MM-dd");
Date date = new DateTime(dateString).toDate();
LambdaQueryWrapper<OrderInfo> queryWrapper = new LambdaQueryWrapper<OrderInfo>(){{
eq(OrderInfo::getReserveDate,date); // 查询就诊日期
ne(OrderInfo::getOrderStatus, OrderStatusEnum.CANCLE.getStatus()); // 查询没有取消的订单
}};
List<OrderInfo> orderInfoList = orderInfoMapper.selectList(queryWrapper);
for(OrderInfo orderInfo : orderInfoList) {
// 短信提示
MsmVo msmVo = new MsmVo();
msmVo.setPhone(orderInfo.getPatientPhone());
// 结合mq快速响应其他模块 发送消息
rabbitService.sendMessage(MqConst.EXCHANGE_DIRECT_MSM, MqConst.ROUTING_MSM_ITEM, msmVo);
}
return ReturnT.SUCCESS;
}
private void init(){
System.out.println("MyJobHandler init >>>>> " + true);
String jobParam = XxlJobHelper.getJobParam();
System.out.println("jobParam = " + jobParam);
}
}
完成规则内的定时任务,到指定时间向就诊人发送消息


调度日志


执行器配置调度中心集群
#调度中心部署地址,多个配置逗号分隔 "http://address01,http://address02"
xxl:
job:
admin:
addresses: http://127.0.0.1:8080/xxl-job-admin,http://127.0.0.1:8081/xxl-job-admin
我们的需求:
解决思路:
其他解决方式

主要参数
// 分片广播任务
// 当前分片数,从0开始,即执行器的序号
int shardIndex = XxlJobHelper.getShardIndex();
//总分片数,执行器集群总机器数量
int shardTotal = XxlJobHelper.getShardTotal();
// 业务逻辑
......
在处理大量数据时,如何高效地存储和查询是我们常面临的挑战。特别是在需要按时间进行统计、分析和展示的数据场景下,数据量往往随着时间的积累而迅速膨胀。为了应对这些挑战,分表技术成为了优化查询性能和管理大规模数据的关键手段。
在实际的开发过程中,针对具有时间维度的大数据表,我们通常会采用按时间进行分表的策略。本文将总结如何实现一个基于时间范围的分表策略,并通过具体的技术实现来展示这一策略在实际系统中的应用。
分表技术是将一个大表拆分成多个小表,以此来提升查询性能和系统的扩展性。常见的分表策略有:
在水平分表中,时间字段(如年、月、日)是一个常见的分片维度。根据业务需求,数据会被拆分成多个按时间命名的表,查询时通过时间范围来确定要查询的具体分表。
以某个数据表(比如"电力消耗数据")为例,我们希望根据时间来进行分表,�将每个月的数据存储到不同的表中。这种策略不仅可以帮助我们高效地管理大规模的数据,还能在查询时避免对整个表的全表扫描,从而提高性能。
假设我们的表名为 electricity_usage_data,我们决定根据月份进行分表。分表规则如下:
electricity_usage_data_yyyyMM,例如:electricity_usage_data_202301、electricity_usage_data_202302 等。为了实现按时间范围的分表,我们需要实现一个分片算法,这个算法的主要作用是根据查询的时间范围,计算出需要访问的分表。通常,这个算法会根据一个起始时间和结束时间,确定哪些表需要被查询。
例如,假设查询的时间范围是从 2023年01月 到 2023年03月,那么分片算法会返回 electricity_usage_data_202301、electricity_usage_data_202302 和 electricity_usage_data_202303 这三个表。
下面是一个基于时间范围的分表算法实现示例。我们使用了Sharding-JDBC来实现这一分片策略,具体代码如下:
@Component
public class MonthRangeShardingAlgorithm implements RangeShardingAlgorithm<String> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
Collection<String> result = new ArrayList<>();
List<String> rangeList = getRangeList(rangeShardingValue);
for (String tableName : rangeList) {
if (collection.contains(tableName.toLowerCase()) || collection.contains(tableName.toUpperCase())) {
result.add(tableName);
}
}
if (result.isEmpty()) {
throw new UnsupportedOperationException("没有匹配到分片表");
}
return result;
}
private List<String> getRangeList(RangeShardingValue<String> rangeShardingValue) {
List<String> rangeList = new ArrayList<>();
String logicTableName = rangeShardingValue.getLogicTableName();
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd");
Range<String> valueRange = rangeShardingValue.getValueRange();
Object start = valueRange.lowerEndpoint();
Object end = valueRange.upperEndpoint();
try {
Date startDate = format.parse(start.toString());
Date endDate = format.parse(end.toString());
DateTime startDateTime = DateUtil.beginOfMonth(startDate);
DateTime endDateTime = DateUtil.beginOfMonth(endDate);
do {
String time = DateUtil.format(startDateTime, "yyyyMM");
String tableName = logicTableName.concat("_").concat(time);
rangeList.add(tableName);
startDateTime = DateUtil.offset(startDateTime, DateField.MONTH, 1);
} while (startDateTime.compareTo(endDateTime) <= 0);
} catch (ParseException e) {
e.printStackTrace();
}
return rangeList;
}
}
doSharding方法:该方法根据输入的时间范围,计算出涉及的所有分表。通过对比表名,筛选出实际需要查询的分表。getRangeList方法:将查询的起始时间和结束时间进行处理,计算出涉及的所有月份,并生成对应的表名。SimpleDateFormat 和 DateUtil 进行时间的格式化和月份的处理。通过 DateUtil.beginOfMonth 获取每个月的第一天,以便统一处理时间范围。该方案的优势在于其动态扩展性。随着数据量的不断增长,新的分表会根据时间自动创建,且查询时会根据实际的时间范围动态计算所需的表,避免了手动干预。
通过将数据分散到多个表中,系统能够更好地进行负载均衡。当某一月份的数据量增大时,可以通过水平扩展(例如增加新的分表)来应对性能瓶颈,而无需对整个表进行迁移或改造。
按时间范围分表的最大优势在于查询效率的提升。当查询某一时间段的数据时,只需要访问相关的分表,而不是对整个数据表进行扫描,从而大大提升了查询速度。
基于时间范围的分表策略在大数据量场景下尤其重要,尤其是在电力等需要处理大量历史数据的行业。通过合理的分表设计,我们可以有效地提升系统性能,优化查询响应时间,确保系统的高可用性和扩展性。这个方案不仅适用于电力行业,也可以广泛应用于任何具有时间维度的大数据场景中。
背景:我们对MongoDB采用的逻辑删除的方案,与MySQL完全不同。 得益于MongoDB擅长储存非结构化数据的优点,即使业务数据结构发生,也不会影响原来的数据,还能保证业务表查询效率。 若MySQL采用此方案,则有业务数据库表结构变动导致数据迁移失败的风险,甚至影响正常业务流程。 综合考虑,关系型数据库适合通过“删除标记”实现逻辑删除,非关系型数据库更适合将“已删除”的数据迁移至回收表中。
举个小demo
首先导入了 MongoDB 驱动,然后创建了一个 MongoDB 客户端(MongoClient),并连接到了本地的 MongoDB 服务器("mongodb://localhost:27017")。通过客户端获取了数据库 "test" 中的集合 "collection"。在逻辑删除代码中,首先通过 ObjectId 创建了一个 ObjectId 对象,其值为 "5f36f47a06c5a722497f37b5"。然后,通过调用 updateOne 方法对该文档进行了逻辑删除操作,即在该文档中添加/更新了一个 "deleted" 字段,该字段的值为 true。
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver-sync</artifactId>
<version>4.0.5</version>
</dependency>
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoClients;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import org.bson.Document;
import org.bson.types.ObjectId;
public class MongoDBLogicDeleteExample {
public static void main(String[] args) {
// 创建 MongoDB 客户端
MongoClient mongoClient = MongoClients.create("mongodb://localhost:27017");
// 获取数据库和集合
MongoCollection<Document> collection = mongoClient.getDatabase("test").getCollection("collection");
// 逻辑删除
ObjectId id = new ObjectId("5f36f47a06c5a722497f37b5");
collection.updateOne(Filters.eq("_id", id), Updates.set("deleted", true));
// 关闭 MongoDB 客户端
mongoClient.close();
}
}
然后在查询代码中,通过调用 find 方法查询 "deleted" 字段不等于 true 的文档,即查询未被逻辑删除的文档。然后,将查询结果存入 documents 集合中。最后,通过循环打印出了查询结果中的每一个文档。最后,关闭了 MongoDB 客户端。
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoClients;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.model.Filters;
import org.bson.Document;
import java.util.ArrayList;
import java.util.List;
public class MongoDBQueryExample {
public static void main(String[] args) {
// 创建 MongoDB 客户端
MongoClient mongoClient = MongoClients.create("mongodb://localhost:27017");
// 获取数据库和集合
MongoCollection<Document> collection = mongoClient.getDatabase("test").getCollection("collection");
// 查询
List<Document> documents = new ArrayList<>();
collection.find(Filters.ne("deleted", true)).into(documents);
// 打印结果
for (Document document : documents) {
System.out.println(document);
}
// 关闭 MongoDB 客户端
如果不想添加字段,可以使用 MongoDB 的另一种实现逻辑删除的方法,即使用软删除。软删除的思想是将文档移动到另一个集合中,而不是真正删除文档。
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import org.bson.types.ObjectId;
import java.util.ArrayList;
import java.util.List;
public class LogicalDeletionExample {
public static void main(String[] args) {
// 创建 MongoDB 客户端
MongoClient mongoClient = new MongoClient("mongodb://localhost:27017");
// 获取数据库
MongoDatabase database = mongoClient.getDatabase("test");
// 获取原始集合
MongoCollection<Document> collection = database.getCollection("collection");
// 获取新集合
MongoCollection<Document> deletedCollection = database.getCollection("deleted_collection");
// 逻辑删除
ObjectId id = new ObjectId("5f36f47a06c5a722497f37b5");
Document deletedDocument = collection.find(new Document("_id", id)).first();
deletedCollection.insertOne(deletedDocument);
collection.deleteOne(new Document("_id", id));
// 查询
List<Document> documents = new ArrayList<>();
collection.find().into(documents);
// 打印结果
for (Document document : documents) {
System.out.println(document);
}
// 关闭客户端
mongoClient.close();
}
}
以上代码通过将文档移动到新集合中,实现了 MongoDB 的逻辑删除,并且不添加字段。
背景:EasyExcel是一个基于Java的简单、省内存的读写Excel的开源项目。在尽可能节约内存的情况下支持读写百M的Excel。它有许许多多的应用场景 例如 数据导入:减轻录入工作量 ;数据导出:统计信息归档 ; 数据传输:异构系统之间数据传输等等
文档地址:https://easyexcel.opensource.alibaba.com
github地址:https://github.com/alibaba/easyexcel
pom中引入xml相关依赖
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
</dependency>
</dependencies>
当引入该依赖之后,会发现在项目的依赖文件中同时多出了poi的类库。也就是说,EasyExcel是基于poi来进行实现的,间接地引入了如下依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
</dependency>
设置表头和添加的数据字段
@Data
public class Stu {
//设置表头名称
@ExcelProperty("学生编号")
private int sno;
//设置表头名称
@ExcelProperty("学生姓名")
private String sname;
}
完成上述功能准备工作之后,我们就可以来生成一个Excel了。
(1)创建方法循环设置要添加到Excel的数据
//循环设置要添加的数据,最终封装到list集合中
private static List<Stu> data() {
List<Stu> list = new ArrayList<Stu>();
for (int i = 0; i < 10; i++) {
Stu data = new Stu();
data.setSno(i);
data.setSname("张三"+i);
list.add(data);
}
return list;
}
(2)实现最终的添加操作
public static void main(String[] args) throws Exception {
String fileName = "E:\\11.xlsx";
// 这里 需要指定写用哪个class去写,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, Stu.class).sheet("写入方法一").doWrite(data());
}
那么我们如何解析Excel呢?接着看....
@Data
public class Stu {
//设置表头名称
//设置列对应的属性
@ExcelProperty(value = "学生编号",index = 0)
private int sno;
//设置表头名称
//设置列对应的属性
@ExcelProperty(value = "学生姓名",index = 1)
private String sname;
}
首先创建一个监听器ExcelListener,集成EasyExcel提供AnalysisEventListener类:
public class ExcelListener extends AnalysisEventListener<Stu> {
//创建list集合封装最终的数据
List<Stu> list = new ArrayList<Stu>();
//一行一行去读取excle内容
@Override
public void invoke(Stu user, AnalysisContext analysisContext) {
System.out.println("***"+user);
list.add(user);
}
//读取excel表头信息
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
System.out.println("表头信息:"+headMap);
}
//读取完成后执行
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
System.out.println("list = " + list);
}
}
在该监听器中,通过重写AnalysisEventListener的方法来获得解析的数据、表头信息,以及解析完毕之后执行的操作信息。
同样写Excel一样,通过EasyExcel类的静态方法来执行读操作:
public static void main(String[] args) throws Exception {
String fileName = "E:\\11.xlsx";
// 这里 需要指定调用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, Stu.class, new ExcelListener()).sheet().doRead();
}
上面提到的@DateTimeFormat注解可转换日期格式,还有其他类似功能的注解和自定义转换器。
起因:随着越来越多的业务转移到互联网上,安全性已经成为任何一个应用程序开发的重要考虑因素。而在 Java 应用程序开发中,Spring Security 是一个非常流行的安全框架,可以提供可靠的身份验证、授权和会话管理等安全特性。无论是开发 Web 应用程序、RESTful 服务、单页应用程序或者其他类型的应用程序,都可以使用 Spring Security 来保护应用程序的安全性。同时,Spring Security 还具有非常好的可扩展性,可以与 Spring 生态系统中的其他框架和库进行无缝集成,使开发人员能够构建出复杂的、高度可定制的安全解决方案。因此,使用 Spring Security 是保障应用程序安全的不二选择。
| Spring Security | Apache Shiro | Apache Knox | Keycloak | Stormpath | |
|---|---|---|---|---|---|
| 概述 | Spring Security 是一个非常流行的 Java 应用程序安全框架,提供了完整的身份验证、授权和会话管理功能。它具有良好的可扩展性和灵活性,能够与 Spring 生态系统中的其他框架和库无缝集成 | Apache Shiro 是一个轻量级的安全框架,提供了身份验证、授权、加密和会话管理等功能。它易于使用和集成,能够与任何应用程序框架一起使用,支持多种数据源,如 LDAP、JDBC 和 Active Directory | Apache Knox 是一个开源网关,提供了 REST API 的认证、授权和审计功能。它可以保护 Hadoop 集群的 REST API,提供了单点登录和 OAuth2 支持 | Keycloak 是一个开��源的身份认证和访问管理解决方案,基于 OpenID Connect 和 OAuth2 协议。它提供了可扩展的身份验证和授权功能,包括单点登录、多因素身份验证和基于角色的访问控制等 | Stormpath 是一个云身份认证和访问管理服务,提供了完整的身份验证、授权和用户管理功能。它可以与任何应用程序框架一起使用,包括 Java、Node.js 和 .NET |
| 优点 | 完整的安全特性、与 Spring 框架无缝集成、丰富的插件和扩展、良好的文档和社区支持 | 括轻量级、易于使用和集成、支持多种数据源、优秀的文档 | 保护 Hadoop 集群的 REST API、支持单点登录和 OAuth2、易于配置和使用 | 可扩展的身份验证和授权功能、多种身份验证方式、基于角色的访问控制、易于使用和部署 | 云身份认证和访问管理服务、易于使用和集成、提供完整的身份验证、授权和用户管理功能 |
| 缺点 | 配置复杂、上手较难 | 与 Spring 框架的深度集成、不够完整的安全特性 | 仅适用于保护 Hadoop 集群的 REST API | 配置复杂、性能较差 | 需要使用云服务、需要支付服务费用,成本高 |
| 适用场景 | 适用于基于 Spring 框架构建的应用程序 | 适用于不依赖于 Spring 框架的应用程序 | 适用于需要保护 Hadoop 集群的 REST API 的场景 | 适用于需要单独部署一个身份认证和访问管理系统的场景 | 适用于需要使用云身份认证和访问管理服务的场景。 |
国内目前非常流行的就是Spring Security和Apache Shiro 。
Spring Security出现的时间较早,在springboot没火起来之前一直都是Shiro 的天下,但目前最能和spring全家桶整合起来的就是Spring Security,Spring Security 是最为完整、可扩展和灵活的安全框架,而且与 Spring 框架的深度集成使得使用和配置变得简单方便。Spring Security 提供了全面的身份验证、授权和会话管理特性,并且可以轻松地扩展到支持自定义的安全策略和特性。而且社区也是十分活跃的。所以此篇文章主要从实践流程出发,实现与spring项目整合的快速搭建解决方案。
相对于 Shiro,在 SSM 中整合 Spring Security 都是比较麻烦的操作,所以,Spring Security 虽然功能比 Shiro 强大,但是使用反而没有 Shiro 多(Shiro 虽然功能没有Spring Security 多,但是对于大部分项目而言,Shiro 也够用了)。自从有了 Spring Boot 之后,Spring Boot 对于 Spring Security 提供了自动化配置方案,可以使用更少的配置来使用 Spring Security。
因此,一般来说,常见的安全管理技术栈的组合是这样的: • SSM + Shiro • Spring Boot/Spring Cloud + Spring Security
如果还想了解shiro这一框架,我也在github开源了一个小demo,用于整合SpringBoot与shiro,实现快速上手,仓库地址:https://github.com/Jachen99/rbac_shiro
Spring 是非常流行和成功的 Java 应用开发框架,Spring Security 正是 Spring 家族中的成员。Spring Security 基于 Spring 框架,提供了一套 Web 应用安全性的完整解决方案。
正如你可能知道的关于安全方面的两个核心功能是“认证”和“授权”,一般来说,Web 应用的安全性包括**用户认证(Authentication)和用户授权(Authorization)**两个部分,这两点也是 SpringSecurity 重要核心功能。
(1)用户认证指的是:验证某个用户是否为系统中的合法主体,也就是说用户能否访问该系统。用户认证一般要求用户提供用户名和密码,系统通过校验用户名和密码来完成认证过程。
通俗点说就是系统认为用户是否能登录
(2)用户授权指的是验证某个用户是否有权限执行某个操作。在一个系统中,不同用户所具有的权限是不同的。比如对一个文件来说,有的用户只能进行读取,而有的用户可以进行修改。一般来说,系统会为不同的用户分配不同的角色,而每个角色则对应一系列的权限。
通俗点讲就是系统判断用户是否有权限去做某些事情。
“Spring Security 开始于 2003 年年底,““spring 的 acegi 安全系统”。 起因是 Spring开发者邮件列表中的一个问题,有人提问是否考虑提供一个基于 spring 的安全实现。
Spring Security 以“The Acegi Secutity System for Spring” 的名字始于 2013 年晚些时候。一个问题提交到 Spring 开发者的邮件列表,询问是否已经有考虑一个基于Spring 的安全性社区实现。那时候 Spring 的社区相对较小(相对现在)。实际上 Spring 自己在2013 年只是一个存在于 ScourseForge 的项目,这个问题的回答是一个值得研究的领域,虽然目前时间的缺乏组织了我们对它的探索。
考虑到这一点,一个简单的安全实现建成但是并没有发布。几周后,Spring 社区的其他成员询问了安全性,这次这个代码被发送给他们。其他几个请求也跟随而来。到 2014 年一月大约有 20 万人使用了这个代码。这些创业者的人提出一个 SourceForge 项目加入是为了,这是在 2004 三月正式成立。
在早些时候,这个项目没有任何自己的验证模块,身份验证过程依赖于容器管理的安全性和 Acegi 安全性。而不是专注于授权。开始的时候这很适合,但是越来越多的用户请求额外的容器支持。容器特定的认证领域接口的基本限制变得清晰。还有一个相关的问题增加新的容器的路径,这是最终用户的困惑和错误配置的常见问题。
Acegi 安全特定的认证服务介绍。大约一年后,Acegi 安全正式成为了 Spring 框架的子项目。1.0.0 最终版本是出版于 2006 -在超过两年半的大量生产的软件项目和数以百计的改进和积极利用社区的贡献。
Acegi 安全 2007 年底正式成为了 Spring 组合项目,更名为"Spring Security"。
要对Web资源进行保护,最好的办法莫过于Filter 要想对方法调用进行保护,最好的办法莫过于AOP。
Spring Security进行认证和鉴权的时候,就是利用的一系列的Filter来进行拦截的。

如图所示,一个请求想要访问到API就会从左到右经过蓝线框里的过滤器,其中绿色部分是负责认证的过滤器,蓝��色部分是负责异常处理,橙色部分则是负责授权。经过一系列拦截最终访问到我们的API。
这里面我们只需要重点关注两个过滤器即可:UsernamePasswordAuthenticationFilter负责登录认证,FilterSecurityInterceptor负责权限授权。
说明:Spring Security的核心逻辑全在这一套过滤器中,过滤器里会调用各种组件完成功能,掌握了这些过滤器和组件你就掌握了Spring Security!这个框架的使用方式就是对这些过滤器和组件进行扩展。
1、给spring-security创建单独的公共模块
2、导入相关jar包,如果是maven工程,直接引入
<!-- Spring Security依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
说明:依赖包(spring-boot-starter-security)导入后,Spring Security就默认提供了许多功能将整个应用给保护了起来:
user的随机密码并打印在控制台上CSRF攻击防护、Session Fixation攻击防护3、在需要使用权限框架的模块导入依赖
这里以医院预约挂号系统的order模块为例,仓库地址:https://github.com/Jachen99/yygh_parent
导入依赖到service-order模块
<dependency>
<groupId>space.jachen</groupId>
<artifactId>spring-security</artifactId>
<version>1.0.1</version>
</dependency>
4、启动该order模块,会发现控制台显示Using generated security password
说明该模块已经被spring security保护。
5、此时我们通过浏览器去访问该模块下的api路径,会进入框架自带的登录页面:

默认用户名为user,密码为控制台输出的随机密码,认证成功后才可以登录。
目前,我们已经实现了自带的登录页面的访问,用户名和密码都来自于内存。那么要访问来自于mysql、redis甚至的用户名、密码怎么办呢?
功能1:自带登录页面,访问真正的数据库,需要做什么?
1、访问基于内存的用户名和密码使用的是InMeoryUserDetailsManager(实现了UserDetailsServer),我们需要自定义UserDetailsServer的实现类。
package space.jachen.yygh.order.security;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.stereotype.Component;
import space.jachen.yygh.security.custom.CustomUser;
import space.jachen.yygh.user.PatientFeignClient;
import space.jachen.yygh.vo.user.LoginVo;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Collection;
/**
* @author JaChen
* @date 2022/12/23 22:35
*/
@Component
public class UserDetailsServiceImpl implements UserDetailsService {
@Resource
private PatientFeignClient userInfoFeignClient;
@Override
public UserDetails loadUserByUsername(String phone) throws UsernameNotFoundException {
LoginVo login = userInfoFeignClient.loginSecurity(phone);
if(login == null) {
throw new UsernameNotFoundException("用户名不存在!");
}
// 这里不比较密码 ,后面通过PasswordEncoder比较
// 返回数据、暂时不做授权
Collection<GrantedAuthority> authorities = new ArrayList<>();
return new CustomUser(login,authorities);
}
}
2、访问数据库的方法loadUserByUsername,返回值为Userdetails,它封装了从数据库中返回的用户信息,但是和我们数据库表不一致,所以我们还需要自定义UserDetails实现类。
package space.jachen.yygh.security.custom;
import lombok.Getter;
import lombok.Setter;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.userdetails.User;
import space.jachen.yygh.vo.user.LoginVo;
import java.util.Collection;
/**
* 访问数据库的方法loadUserByUsername,返回值为Userdetails,
* 它封装了从数据库中返回的用户信息,但是和我们数据库表不一致,
* 所以我们还需要自定义UserDetails实现类。
*
* @author JaChen
* @date 2022/12/23 22:31
*/
@Getter
@Setter
public class CustomUser extends User {
/**
* 我们自己的用户实体对象,要调取用户信息时直接获取这个实体对象
*/
private LoginVo loginVo;
/**
*
* @param loginVo 从数据库中查询的用户信息
* @param authorities 从数据库中查询的权限
*/
public CustomUser(LoginVo loginVo,Collection<? extends GrantedAuthority> authorities) {
super(loginVo.getPhone(), loginVo.getCode(), authorities);
this.loginVo = loginVo;
}
}
现在数据都有了,我们需要进行密码的比较。
3、使用PasswordEncoder接口,但是不同的数据库采用的加密算法不同,这里可以使用security自带的PasswordEncoder实现类,如果不合适,就自定义一下PasswordEncoder的实现类即可。
package space.jachen.yygh.security.custom;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.security.crypto.password.PasswordEncoder;
import org.springframework.stereotype.Component;
/**
*
* 自定义密码组件 密码处理
* 此项目不需要md5加密处理
* 不需要开发者自己调用此类,SpringSecurity流程中进行密码比较时会自动调用。
*
* @author JaChen
* @date 2022/12/23 22:25
*/
@Component // 必须添加到IOC ,SpringSecurity才可以使用
public class CustomPasswordEncoder implements PasswordEncoder {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 如果需要加密进行加密操作后返回,这里不需要处理,
* 因为本项目没有对用户密码进行加密,
* 采用的是手机号+验证码的方式进行登录
* 验证码存在redis中,为了方便演示,特定此条验证码永不过期,当作密码使用,
*
* @param rawPassword 明文 用户输入的密码
* @return 密文
*/
public String encode(CharSequence rawPassword) {
return rawPassword.toString();
}
/**
*
* @param rawPassword 用户输入的密码 即4位验证码
* @param encodedPassword 从redis中查询出来的验证码
* @return boolean
*/
public boolean matches(CharSequence rawPassword, String encodedPassword) {
// 写死
encodedPassword = stringRedisTemplate.opsForValue().get("13243922402");
return encodedPassword.equals(encode(encodedPassword));
}
}
先来看看整个认证的流程图:
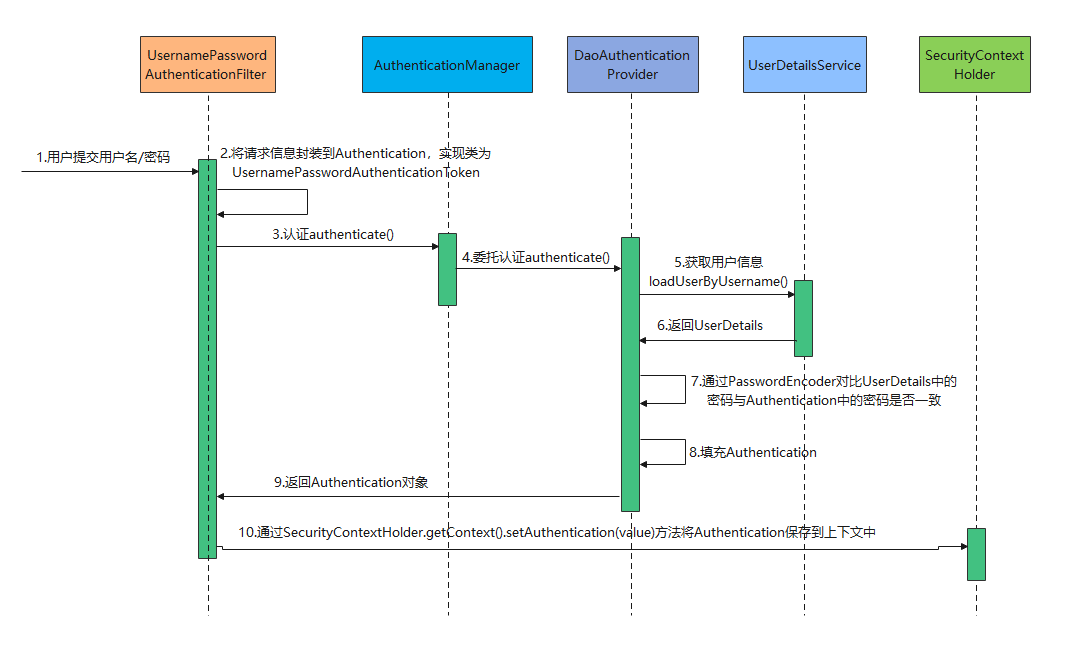
现在,虽然已经实现了对真实数据库的访问,但是还是使用自带的登录页面,那么怎么才能通过前端项目的真实的用户登录页面访问呢?
登录成功后,每次访问其他资源都要判断一下token是否正确,如果正确才能访问,如果不正确返回异常信息。
4、自定义用户认证接口(过滤器1)
// 不用加Component注解 不需要加入IOC 过滤器由tomcat进行管理
package space.jachen.yygh.security.filter;
/**
* @author JaChen
* @date 2022/12/23 22:45
*/
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.security.authentication.AuthenticationManager;
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.AuthenticationException;
import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter;
import org.springframework.security.web.util.matcher.AntPathRequestMatcher;
import space.jachen.yygh.common.result.JsonData;
import space.jachen.yygh.common.result.ResultCodeEnum;
import space.jachen.yygh.common.utils.JwtHelper;
import space.jachen.yygh.common.utils.ResponseUtil;
import space.jachen.yygh.security.custom.CustomUser;
import space.jachen.yygh.vo.user.LoginVo;
import javax.annotation.Resource;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* <p>
* 登录过滤器,继承UsernamePasswordAuthenticationFilter,对用户名密码进行登录校验
* </p>
*
*/
public class TokenLoginFilter extends UsernamePasswordAuthenticationFilter {
@Resource
private RedisTemplate redisTemplate;
public TokenLoginFilter(AuthenticationManager authenticationManager,
RedisTemplate redisTemplate ) {
//设置认证管理器
this.setAuthenticationManager(authenticationManager);
//设置登录的地址和请求方式
this.setRequiresAuthenticationRequestMatcher(
new AntPathRequestMatcher("/yygh/user/loginSecurity", "POST"));
this.redisTemplate = redisTemplate;
}
/**
* 登录认证
* 走这个登录认证流程 不走原先的登录接口了
*
* @param req
* @param res
* @return
* @throws AuthenticationException
*/
@Override
public Authentication attemptAuthentication(HttpServletRequest req, HttpServletResponse res)
throws AuthenticationException {
try {
// 获取用户名的方法 简单封装方法
LoginVo loginVo = new ObjectMapper().readValue(req.getInputStream(), LoginVo.class);
String pwd = (String) redisTemplate.opsForValue().get(loginVo.getPhone());
// 将用户名和密码封装到Authentication
Authentication authenticationToken =
new UsernamePasswordAuthenticationToken(loginVo.getPhone(), pwd);
// 调取getAuthenticationManager认证
return this.getAuthenticationManager().authenticate(authenticationToken);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 登录成功 认证成功调用的方法
*
* @param request
* @param response
* @param chain
* @param auth
* @throws IOException
* @throws ServletException
*/
@Override
protected void successfulAuthentication(HttpServletRequest request, HttpServletResponse response, FilterChain chain,Authentication auth) throws IOException, ServletException {
// 1、通过Authentication获取认证的对象
CustomUser customUser = (CustomUser) auth.getPrincipal();
// 2、通过JwtHelper生成token
String token = JwtHelper.createToken(Long.parseLong(customUser.getLoginVo().getOpenid()), customUser.getLoginVo().getPhone());
// 3、获取用户的权限
// Collection<GrantedAuthority> authorities = customUser.getAuthorities();
// 4、将权限保存到Redis中
// redisTemplate.boundValueOps(customUser.getUsername()).set(authorities);
// 5、保存登录日志
// loginLogService.recordLoginLog(customUser.getUsername(), IpUtil.getIpAddress(request),1,"登录成功");
// 创建一个Map
Map<String, Object> map = new HashMap<>();
map.put("token", token);
// 6、通过ResponseUtil工具类响应到前端
ResponseUtil.out(response, JsonData.ok(map));
}
/**
* 登录失败
*
* @param request
* @param response
* @param e
* @throws IOException
* @throws ServletException
*/
@Override
protected void unsuccessfulAuthentication(HttpServletRequest request, HttpServletResponse response, AuthenticationException e) throws IOException, ServletException {
if (e.getCause() instanceof RuntimeException){
ResponseUtil.out(response, JsonData.build(null,204,e.getMessage()));
}else {
ResponseUtil.out(response,JsonData.build(null, ResultCodeEnum.LOGIN_MOBLE_ERROR));
}
}
}
// 如果想在里面加入@Autowired 则需要添加配置类
package space.jachen.yygh.security.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.builders.WebSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.config.http.SessionCreationPolicy;
import space.jachen.yygh.security.filter.TokenLoginFilter;
import javax.annotation.Resource;
/**
* @author JaChen
* @date 2022/12/23 22:24
*/
@Configuration
@EnableWebSecurity //@EnableWebSecurity是开启SpringSecurity的默认行为
@EnableGlobalMethodSecurity(prePostEnabled = true)//开启注解功能,默认禁用注解
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Resource
private RedisTemplate redisTemplate;
@Override
protected void configure(HttpSecurity http) throws Exception {
// 这是配置的关键,决定哪些接口开启防护,哪些接口绕过防护
http
//关闭csrf
.csrf().disable()
// 开启跨域以便前端调用接口
.cors().and()
.authorizeRequests()
// 指定某些接口不需要通过验证即可访问。登陆接口肯定是不需要认证的
.antMatchers("/yygh/user/login").permitAll()
// 这里意思是其它所有接口需要认证才能访问
.anyRequest().authenticated()
.and()
//TokenAuthenticationFilter放到UsernamePasswordAuthenticationFilter的前面,
// 这样做就是为了除了登录的时候去查询数据库外,其他时候都用token进行认证。
// .addFilterBefore(new TokenAuthenticationFilter(redisTemplate), UsernamePasswordAuthenticationFilter.class)
.addFilter(new TokenLoginFilter(authenticationManager(), redisTemplate));
//禁用session
http.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS);
}
/**
* 配置哪些请求不拦截
* 排除swagger相关请求
* @param web
* @throws Exception
*/
@Override
public void configure(WebSecurity web) throws Exception {
web.ignoring().antMatchers("/favicon.ico","/swagger-resources/**", "/webjars/**", "/v2/**", "/swagger-ui.html/**", "/doc.html");
}
}
5、配置用户认证 (过滤器2)
package space.jachen.yygh.security.filter;
/**
* @author JaChen
* @date 2022/12/23 23:04
*/
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.util.StringUtils;
import org.springframework.web.filter.OncePerRequestFilter;
import space.jachen.yygh.common.result.JsonData;
import space.jachen.yygh.common.result.ResultCodeEnum;
import space.jachen.yygh.common.utils.JwtHelper;
import space.jachen.yygh.common.utils.ResponseUtil;
import javax.annotation.Resource;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.Collection;
/**
* <p>
* 认证解析token过滤器
* </p>
*/
public class TokenAuthenticationFilter extends OncePerRequestFilter {
@Resource
private RedisTemplate redisTemplate;
public TokenAuthenticationFilter(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain chain)throws IOException, ServletException {
logger.info("认证解析token过滤器的url:"+request.getRequestURI());
//如果是登录接口,直接放行
if("/yygh/user/login".equals(request.getRequestURI())) {
chain.doFilter(request, response);
return;
}
UsernamePasswordAuthenticationToken authentication = getAuthentication(request);
if(null != authentication) {
SecurityContextHolder.getContext().setAuthentication(authentication);
//放行请求
chain.doFilter(request, response);
} else {
ResponseUtil.out(response, JsonData.build(null, ResultCodeEnum.PERMISSION));//209 没有权限
}
}
private UsernamePasswordAuthenticationToken getAuthentication(HttpServletRequest request) {
// token置于header里
String token = request.getHeader("token");
logger.info("token:"+token);
if (!StringUtils.isEmpty(token)) {
String username = JwtHelper.getUserName(token);
logger.info("username:"+username);
if (!StringUtils.isEmpty(username)) {
//从Redis中获取权限
Collection<GrantedAuthority> authorities = (Collection<GrantedAuthority>) redisTemplate.boundValueOps(username).get();
return new UsernamePasswordAuthenticationToken(username, null, authorities);
//返回一个认证对象
//return new UsernamePasswordAuthenticationToken(username, null, Collections.emptyList());
}
}
return null;
}
}
现在就可以通过swagger测试登录了。
背景:因为日常工作和学习中难免会与数据库打交道,其中如何快速的从庞大的数据库中精准的查找到我们想要的信息一直是很热的话题,所以写下此篇笔记,亦在不断地积累有关数据库查询优化方面的经验,从而能高效的使数据传递给外界,给用户更好的体验,这篇文章会一直更新下去。
stackoverflow链接: https://stackoverflow.com/questions/13750475/sql-performance-union-vs-or)
当SQL语句有多个or语句时,可以考虑使用union或者union all代替来提高速度。使用or的SQL语句往往无法进行优化,导致速度变慢。但这不是固定的,有时候使用or速度会更快些。具体情况还要经过测试为准。如果加索引的话,也可能实现速度优化。
实验表格如下,实际数据有2,000,000条,从里面返回大约最多1000行左右的数据。
| X | Y | Inline | CDP | T |
|---|---|---|---|---|
| 12002400 | 5801000 | 300 | 300 | 3400 |
| 12002408 | 5801005 | 300 | 301 | 3402 |
| 12002416 | 5801010 | 300 | 302 | 3404 |
| 12002424 | 5801015 | 300 | 303 | 3406 |
| ... | ... | ... | ... | ... |
or语句(部分节选)
SELECT * FROM tablename where (cdp= 300 and inline=301) or (cdp= 301 and inline=301) or (cdp= 302 and inline=301) or (cdp= 303 and inline=301) or (cdp= 304 and inline=301) or (cdp= 305 and inline=301) or (cdp= 306 and inline=301) or (cdp= 307 and inline=301)
union all语句(部分节选)
SELECT * FROM tablename where (inline= 300 and cdp=300) union all SELECT * FROM tablename where (inline= 301 and cdp=300) union all SELECT * FROM tablename where (inline= 302 and cdp=300) union all SELECT * FROM tablename where (inline= 303 and cdp=300) 返回不规则的900条数据,前者用了60多秒,后者用了8秒左右。
总结:
2023/02/09
shell脚本
#!/bin/bash
echo "请输入字段servnumber的值:"
read serber
echo "请输入创建sql语句的数量:"
read number
# char=`head /dev/urandom | tr -dc 0-9 | head -c 11`
for (( i=0;i<$number;i++ ))
do
pass=`head /dev/urandom | tr -dc a-z | head -c 8`
let serber=serber+1
echo "insert into test(id,username,servnumber,password,createtime) values('$i','user${i}','${serber}','$pass',now());" >>sql1.txt
done
尽量避免使用select *from ,尽量精确到想要的结果字段。 尽量避免条件使用or。 记得加上limit 限制行数,避免数据量过大消耗性能。 使用模糊查询时,%放在前面是会使索引失效。 要小心条件字段类型的转换。
2023/02/11
最好 nginxi访问日志,流量重放在测试环境中;迫不得已再线上调
mysql> show variables like 'slow%';
+---------------------+--------------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------------+
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | /data/mydata/jachen-public-slow.log |
+---------------------+--------------------------------------+
set global slow_query_log = on ;
日志路径也可以自定义:
set global slow_query_log_file = '路径';
show variables like '%long%';
set long_query_time=0.4;
永久生效的设置方法:修改配置文件 vi /etc/my.cnf
[mysqld]
slow_query_log = 1
long_query_time = 0.1
slow_query_log_file =/usr/local/mysql/mysql_slow.log
最后重新连接才能生效,不必重启服务器!
执行耗时sql:
SELECT * FROM emp;
SELECT * FROM emp WHERE deptid > 1;
查询慢查询记录数:
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
查询日志:
vim /var/lib/mysql/bogon-slow.log
mysqldumpslow分析工具:
在生产环境中,如果要手�工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow。退出mysql命令行,执行以下命令:
-- 查看mysqldumpslow的帮助信息
mysqldumpslow --help
-- 工作常用参考
-- 1.得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/bogon-slow.log
-- 2.得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/bogon-slow.log
-- 3.得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/bogon-slow.log
-- 4.另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/bogon-slow.log | more
-a: 将数字抽象成N,字符串抽象成S
-s: 是表示按照何种方式排序
-t: 即为返回前面多少条的数据
-g: 后边搭配一个正则匹配模式,大小写不敏感的
2023/02/15

介绍如何开启性能详情
mysql> show variables like '%profiling%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| have_profiling | YES |
| profiling | OFF |
| profiling_history_size | 15 |
+------------------------+-------+
set profiling = on ;
mysql> show profiles;
+----------+------------+---------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------+
| 1 | 0.00177775 | show variables like '%profiling%' |
| 2 | 0.00037900 | select * from test where id='087878' |
| 3 | 0.34618025 | select * from test where servnumber='1367008787' |
| 4 | 0.31986825 | select * from test where servnumber='13670087879' |
+----------+------------+---------------------------------------------------+
mysql> show profile for query 4;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000100 |
| checking permissions | 0.000010 |
| Opening tables | 0.000023 |
| init | 0.000045 |
| System lock | 0.000015 |
| optimizing | 0.000016 |
| statistics | 0.000028 |
| preparing | 0.000020 |
| executing | 0.000006 |
| Sending data | 0.319489 |
| end | 0.000037 |
| query end | 0.000012 |
| closing tables | 0.000012 |
| freeing items | 0.000040 |
| cleaning up | 0.000017 |
+----------------------+----------+
性能线程的详细解释官方文档链接:https://dev.mysql.com/doc/refman/5.7/en/general-thread-states.html
2023/02/16
1、字段不添加null 都是not null,默认值

2、把字段都设置为not null ,添加特殊字段,把数据存储j为JSON格式
2023/02/18
1、保证被驱动表的JOIN字段已经创建了索引 2、需要JOIN 的字段,数据类型保持绝对一致。 3、LEFT JOIN 时,选择小表作为驱动表,大表作为被驱动表 。减少外层循环的次数。 4、INNER JOIN 时,MySQL会自动将小结果集的表选为驱动表 。选择相信MySQL优化策略。 5、能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数) 6、不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询。 7、衍生表建不了索引
2023/02/19
使用连接(JOIN)查询来替代子查询。**连接查询不需要建立临时表 ,其速度比子查询 要快 ,如果查询中使用索引的话,性能就会更好. 例如:尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代
2023/02/22
2023/02/28
背景:我们通常理解的mysql5.7过渡到8.0是由于查询缓存很鸡肋,要保证每次查询都是相同的sql查询语句,命中率自然会很低。但是真的只是因为这个原因吗?那么我要是在高并发下请求同一sql的场景这显然也是存在的,那为什么还要去掉这层缓存呢?
MySQL 8.0 在缓存方面也进行了一些改变,以下是一些主要变化:
其中第三点提到了 MySQL 8.0 引入了更好的查询缓存机制,用于缓存查询结果,这与之前的版本不同,MySQL 8.0 不再使用全局查询缓存,而是改为使用基于查询语句的缓存。这里我们具体展开来看看这个变化。
在之前的 MySQL 版本中,查询缓存是一种可用于缓�存 SELECT 语句的结果集的机制。这个机制通过在内存中缓存查询结果集,以便在以后执行相同的查询时可以直接从缓存中读取结果集,而无需执行查询。这种机制可以大大提高查询性能,特别是在有大量重复查询的情况下。
然而,MySQL 8.0 中的查询缓存与之前版本不同,它不再使用全局查询缓存,而是改为使用基于查询语句的缓存。具体来说,每个查询都会被单独缓存,并且只有相同的查询(包括查询语句和参数)才能从缓存中获取结果集。这种机制可以避免之前版本中遇到的一些问题,比如全局查询缓存锁和内存分配问题。
另外,MySQL 8.0 还支持对查询缓存进行更细粒度的控制,包括可以对某些查询禁用查询缓存,可以在查询语句中指定查询结果集是否需要被缓存等。
虽然 MySQL 8.0 引入了基于查询语句的缓存机制,但是需要注意的是,查询缓存并不总是对性能有益。对于一些查询频率低、数据更新频繁的情况,缓存可能会浪费内存,而不是提高性能。因此,需要根据具体情况来评估是否使用查询缓存。
我们先来看看mysql5.7服务端获取客户端请求的基本流程,查询缓存是在解析与优化模块的开始位置,也就意味着它是以全局查询缓存存在的,那么这样有什么弊端呢?它能否保证高并发写的读写一致呢?
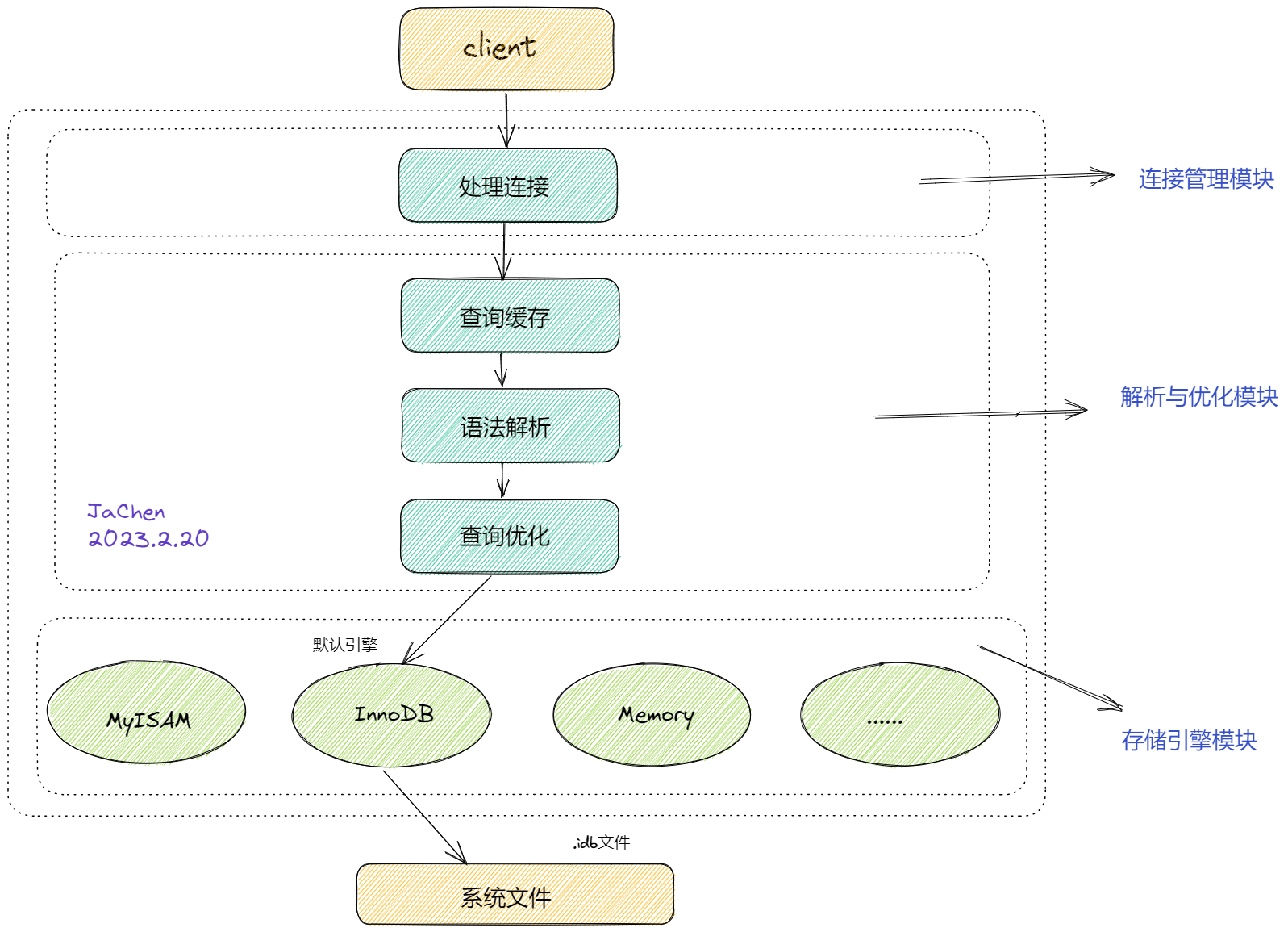
在高并发下查询同一个sql语句select *from user where id = 1;那么存在查询缓存的确可以提高查询的效率,这是我们普遍认为的正常情况。但是在不正常的情况下是会出大问题的,如果我们已经在内存中的数据在磁盘中进行了update修改,我们就必须要使我们缓存中的数据更新,保证数据的一致性,但是在mysql5.7中,对内存是没有管理策略的,内存中数据的生效、失效、过期都没有进行标记。那么如果不能保证缓存数据的一致性就会查到脏数据,如果我们是在对数据一致性要求不高的场景下的程序,那么使用查询缓存是不影响的,总不能正在玩着游戏,你停机游戏对数据进行更新?
我们的排序,大数据量的查找,order by ,join操作等,join是左表去匹配右表,左表拿出一行数据到右表一一对比,这个比的过程是绝对不会从磁盘中一一拿出来比的,它底层会把数据加载到内存的缓冲区buffer中,再进行比较。
处理连接的瓶颈中并发连接数会有限制,比如500个线程,虽然它从缓存内存中取很快,但是对于select语句,只要做好优化,比如创建好索引,在磁盘中取也是不慢的,而且mysql底层的磁盘是有机的组合的,并且在高频的访问中,它也会有读buffer,甚至还存在写buffer,如果读buffer中的数据没有被修改,它每次也是在内存中读的,也不会在磁盘中读,所以就没必要再加查询缓存了。
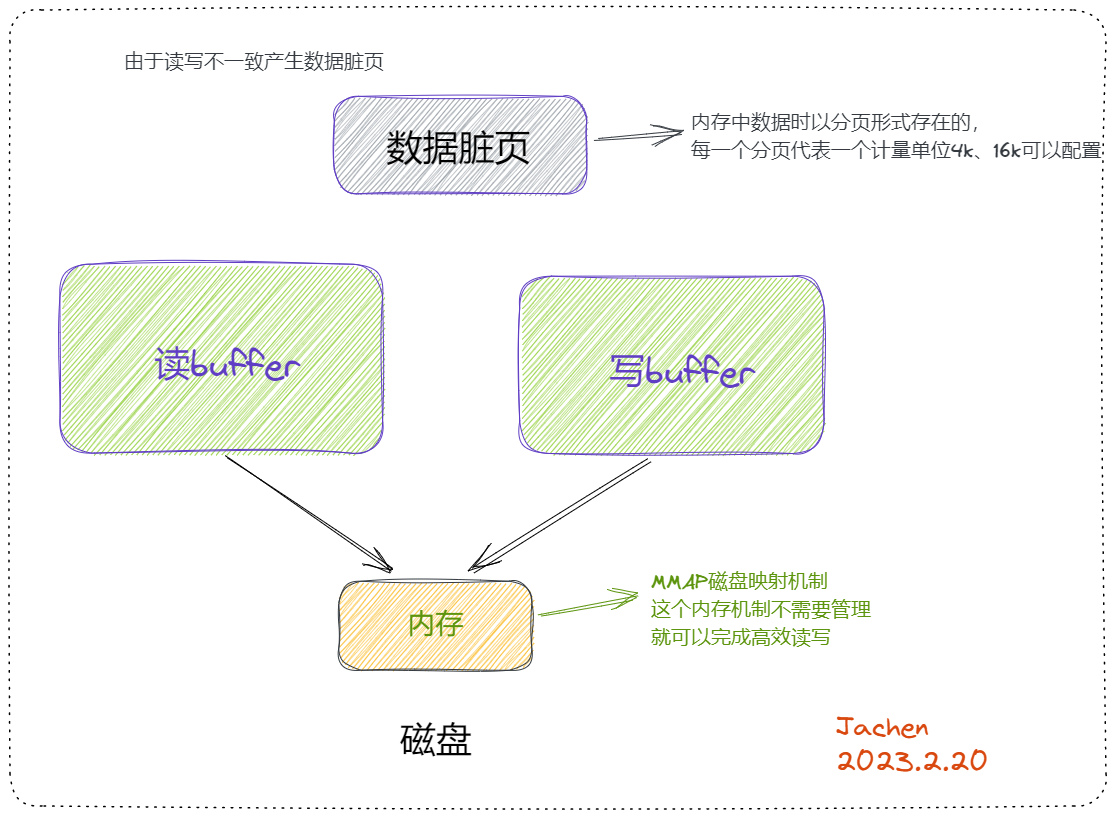
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 。只有相同的SQL语句才会命中查询缓存。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。在两条查询之间 有 INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE 语句也会导致缓存失效,所以在MySQL 8之后就抛弃了这个功能。
如果一张表中有8000万条数据,查询缓存显然就会力不从心,如果只存热点数据呢?即便是使用lru算法,我们也无法确定已经存在mysql的缓存数据,即便我们缓存了10w条数据,但是我们不知道是8000w条中的哪一个,就会发生缓存穿透,无法命中。加缓存集群更是无从谈起,所以mysql8.0就直接废弃了。
应用层组织缓存,最简单的是使用redis,ehcached等
缓存的意义在于快速查询提升系统性能,可以灵活控制缓存的一致性 8.0之前让DBA一直禁用的mysql缓存的限制: